

















Artificial intelligence (AI) is undeniably changing the insurance industry. Carriers are justifiably enthusiastic about the opportunities for improved efficiency and cost savings. Unfortunately, the conversation about these benefits often revolves around the idea of AI as a replacement for humans—e.g., https://willrobotstakemyjob.com/ where jobs categories of “insurance underwriters” and “claims adjusters, examiners and investigators” are given an Automation Risk Level of “You are doomed.”
This is overselling the capabilities of AI and underselling the deep knowledge and experience of human underwriters and adjusters. AI is best thought of as complements to these experts. Understanding this will promote realistic expectations and avoid turning underwriters and adjusters against innovative AI solutions.
One application of AI that best illustrates the potential to augment expert decision-making is natural language processing (NLP). NLP is a fast-growing subfield of artificial intelligence that can help insurers harness the goldmine of internal knowledge contained in unstructured text data. This information can provide nuance and fill gaps in standard structured data.
For example, a commercial insurer might categorize a business according to its industry: service, retail, manufacturing, etc. This categorization is useful but limited. A written description of the company’s operations might offer additional information to differentiate this business and the risks it presents and faces. While an underwriter may already incorporate this knowledge when evaluating a policy, NLP techniques can add consistency to the way this internal knowledge is applied. It also can synthesize the information an underwriter or adjuster needs to process and make better decisions.
While insurers seem to recognize the potential in these text sources, realization of this potential has proven more challenging than expected as illustrated in Willis Towers Watson’s 2019/2020 P&C Advanced Analytics Survey. In personal and commercial lines, the percentage of companies taking advantage of unstructured claim and underwriting information lagged expectations in 2019. However, insurers remained optimistic when looking ahead to 2021.
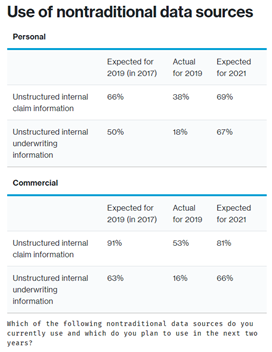 In order to justify this optimism, insurers will need to overcome the challenges inherent to unstructured text data:
In order to justify this optimism, insurers will need to overcome the challenges inherent to unstructured text data:
- “Junk” words that do not contribute to the meaning of a sentence, like “the” and “to.”
- Polysemy: words with more than one meaning.
- Synonyms: words with the same meaning.
- Negation.
- Abbreviations and acronyms, which often differ by industry and region.
- The volume of text to analyze.
However, with advances in AI, NLP is now capable of reading, deciphering, understanding language and gaining valuable insights from it. Insurers can look to this technology for a range of techniques, from simple to highly complex, which unlock this previously underutilized data source. In addition to processing and cleaning up text to make it more readable for machines, NLP provides various approaches to derive features that add value to predictive models and other analytical efforts. These techniques have proven valuable for underwriting and claims contexts, as illustrated in two case studies.
Improving underwriting models using topic model features
Many commercial carriers are looking to augment their underwriting decisions with predictive models. In addition to the structured data fields available for modeling, such as industry codes or geodemographic variables, there is significant information contained in underwriting reports and loss control surveys. Mining these reports can shed light on a company’s attitude toward safety or add nuance to generic industry codes. This information can form the basis for key explanatory variables to be included in predictive models that target underwriting segmentation.
The simplest approach to generate predictive features is word or phrase counts. For example, how many times is the phrase “drug testing” mentioned in a policy’s loss control survey? These features can help identify important concepts that might not be captured in structured data. However, because they capture only a specific word or phrase, they suffer from a lack of context. Phrases with similar but slightly different wording will be missed.
A more sophisticated approach that helps address this issue is topic modeling, a clustering algorithm that attempts to understand the themes of a document. Topic modeling algorithms identify commonly co-occurring words that define “topics” in the text. Instead of simply searching for the phrase “safety program,” a topic model can identify a topic centered around words and phrases such as “safety program,” “safety training,” “certified,” “written safety plan,” “safety meetings,” etc.
The topic model assigns to each document a distribution of the identified topics. For example, the underwriting report for a policy might be broken down into 40 percent for a topic about farming activities like harvesting, planting and growing; 30 percent for a topic about drug testing, background checks and physicals; and 30 percent for a topic about farming equipment like grain elevators, mills and seed bins.
These percentages can be used as features in predictive models and present more context and distinction than word or phrase indicators. Topic features have been found to add significant value to commercial underwriting models. In one workers compensation model, generated topics were the third most predictive group of variables, adding almost as much incremental value as traditionally predictive variables like class code and hazard group.
Identifying similar historical claims using sentence embeddings
Text mining can aid analyses other than predictive models. In the claims application, NLP techniques can enable a comparison between claims based on their claim notes.
Word embeddings encompass a variety of techniques that generate numerical representations of text. Certain complex techniques, like transformers, can handle long-range word dependencies. For example, a word like “ambulance” would have a different representation when negation occurs, as in the sentence “claimant did not require or request an ambulance.” Words and phrases are represented as vectors of numbers. To illustrate, the word “laceration” might be represented by the vector (0.15, 0.29, 0.18, 0.54, … 0.87). Words with similar meanings will have similar representations. The similarity of two documents, such as two claim notes, can be determined by calculating the difference between their respective vectors.
When a claim adjuster is evaluating a new claim, historical claims with similar causes or similar injuries can be presented as additional background for how to handle the claim. Decisions about claim triage or the most appropriate case reserve could be based on the results of those similar historical claims.
NLP delivers new insights and improves decision-making
There are many other applications for NLP to support the decision-making of underwriters and adjusters. For example, text data can be used to correct data entry errors in a policy’s application or identify subrogation opportunities.
NLP is a key area of AI that can make the most of the wealth of accumulated employee knowledge. Rather than replacing them, AI offers an opportunity to make a company’s experts more efficient and more consistent. By recognizing this, carriers can realize the benefits of implementing AI solutions without alienating key sources of internal expertise. The domain knowledge retained by underwriters and adjusters will improve AI performance, and in turn, AI will impart new insights to underwriters and adjusters, making them more effective decision-makers.
Insurers that find ways to capitalize on innovations in NLP will reap the “golden nuggets” of a more enlightened and efficient workforce of decision-makers.
 AI Adoption Continues, But 70% Want More Training: SMB Survey
AI Adoption Continues, But 70% Want More Training: SMB Survey  Deep Dive: Understanding Data Center Perils
Deep Dive: Understanding Data Center Perils  Ranking: Who Are the Insurance Industry’s AI Talent, Maturity Leaders?
Ranking: Who Are the Insurance Industry’s AI Talent, Maturity Leaders?  AI Pushes Underwriting Beyond Risk Selection to Prevention
AI Pushes Underwriting Beyond Risk Selection to Prevention 








