



















This is the sixth in a series of articles by Valen Analytics looking at the hurdles that insurers must overcome to effectively implement and gain value from data analytics programs.
Executive Summary
Third-party data providers are abundant, but how do you decide which ones merit investments of money and resources? Here, Kirstin Marr of Valen Analytics identifies two types of external data—transactional and behavioral—as she gives advice to answer the question and outlines an approach for combining internal and external data sources with synthetic variables for better predictive horsepower.
There is no shortage of third-party data providers, but determining the sources in which to invest, what questions to ask during data collection and what approach combines various data sources for the best market predictors will determine success in today’s competitive landscape.
Calculating the ideal combinations of available data is the trick in building powerful and highly predictive models. Here are a few tips to help source data.
Data Testing Leads to Robust Models and Desired Outcomes
Insurers are increasingly looking to data to more efficiently assess risk and enhance the customer experience by asking fewer questions and returning quotes in real time. Two of the most common resources successful carriers employ to get a clearer picture of the risk landscape are transactional and behavioral data.
Simply put, transactional data captures a historical record of a customer’s transactions, like insurance claims and payments. Behavioral data provides insights into customers’ habits, like how they tend to drive.
Unlike static data such as geography or survey-based data, which only offer data based on a set sample of respondents, behavioral and transactional data offer granular insights into how a customer’s behavior has evolved over time and can help gather real-time actionable insights resulting in better risk assessment. Both types of data are valuable in building predictive models.
To create the most robust models, iterative testing is used to test several data sets against multiple models that were built and “trained” on data sets with different business goals. These data sets include various combinations of in-house and third-party data gathered from different sources. This type of testing and re-testing helps to develop the data sets that can provide the best insights for any given problem statement. This approach illustrated in the diagram below identifies the most predictive variables and the data that informs them.
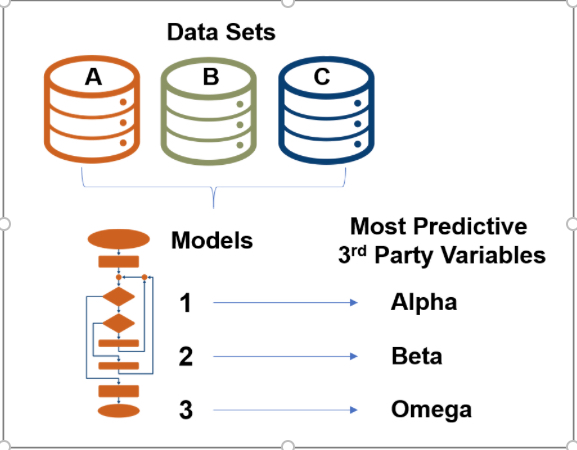
Data Selection and What It Entails
Several key factors should be evaluated when considering third-party data sources for model building. The first is level of granularity. Rating bureaus offer large amounts of data, though it’s aggregated according to specific definitions and segments the rating bureau is using. This limits an insurer’s ability to analyze and apply to different types of predictive models. Conversely, other third-party data sources offer flexibility but lack scale or are not available at the time of quoting.
Making decisions regarding scale versus value is crucial to insurers’ data initiatives. A large data set is typically a great asset. When insurers have substantial additional information in reserve, they can pull usable correlations from this reserve for the predictive model. The challenge is finding the data that’s most actionable.
Another factor to consider when assessing which data repositories provide the best cost/benefit, is the cost of managing transactional data given how it changes structurally over time. It’s crucial to streamline the processes of gathering, cleansing and restructuring data because manual data management is an expensive process.
Synthetic Variables and Where They Come Into Play
Data volume can be both a blessing and a curse. A large pool of data means more data to sift through, wrangle and maintain but also allows for the transformation of large data sets into highly predictive, compound variables. Insurers stand to significantly benefit from understanding the variable selection process and evaluate risks and rewards.
By supplementing in-house data with a large pool of transactional third-party data, data providers are able to create granular synthetic variables that add better predictive horsepower to a model. Synthetic variables refer to manually constructed variables from computations of more than one variable. In fact, leveraging synthetic variables from large pools of data can provide up to 13 times the predictive power compared to policy-only data from one insurer, according a recent study conducted by Valen.
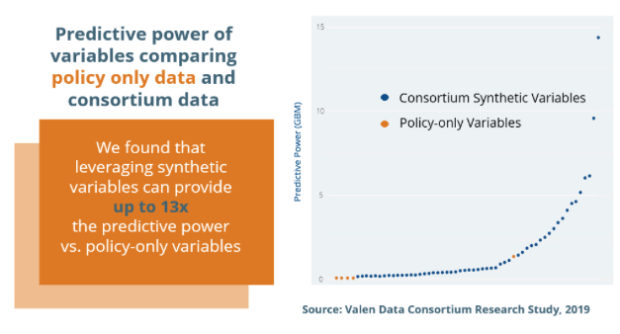
Access to larger data sets creates new opportunities for repeated testing, which inherently generates better predictors. Equally important is the ability to quickly test against other data sets to create new calculations and refresh or upgrade models as needed.
- How to Identify and Overcome Bias in a Predictive Model
- 4 Ways Execs Can Increase Underwriters’ Embrace of Predictive Analytics
- How to Fuel Growth Without a New Business Penalty: Put Down the Predictive Model Shotgun
- Note to Insurers: Put Down Your Spreadsheets
- Carrier Predictive Analytics Initiatives: Telling a Clear Story to Agents
However, there’s a dearth of providers capable of handling data as well as creating predictive models in today’s insurance market. As a result, insurers looking for the benefits of an integrated approach of sophisticated data analytics and modeling capabilities stand to benefit the most from a build/buy hybrid approach.
With data fueling better informed decisions, savvy insurers are able to quantify the value and unlock optimal insights through the right combination of external and transactional data to add to their analytics capabilities.
 Beazley Agrees to Zurich’s Sweetened £8 Billion Takeover Bid
Beazley Agrees to Zurich’s Sweetened £8 Billion Takeover Bid  Nearly 26.2M Workers Are Expected to Miss Work on Super Bowl Monday
Nearly 26.2M Workers Are Expected to Miss Work on Super Bowl Monday  RLI Inks 30th Straight Full-Year Underwriting Profit
RLI Inks 30th Straight Full-Year Underwriting Profit  Six Forces That Will Reshape Insurance in 2026
Six Forces That Will Reshape Insurance in 2026 
