


















Given the complexity of catastrophe models, at first it might seem impossible for you to build your own. This was certainly the case 10-20 years ago. But technology has changed since the first-generation models were developed, and the past several years have seen advancements that are dramatically changing the landscape of modeling.
Executive Summary
Can you build your own catastrophe model? Risk modeling pioneer Karen Clark says yes, laying out the reasons for doing it and steps in the process.In the early days of modeling there was no email or Internet, and there was a lot of labor involved in simply finding and preparing the scientific data and other information needed for a model. For example, detailed soil data necessary for the earthquake models had to be manually digitized from paper maps. In contrast, just this year the U.S. Geological Survey released a database of high-resolution soil data for the entire world, and it’s freely available and easily accessible.
Fundamentally, a catastrophe model is a straightforward structured framework for loss estimation, and for every peril region, the models have the same four components as shown below.
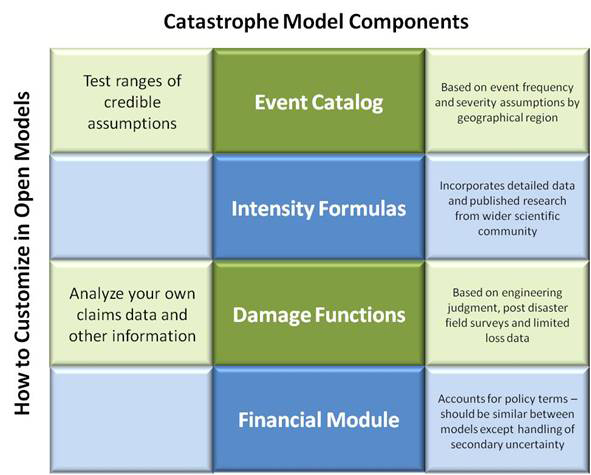
The event catalog defines the frequency and physical severity of events by geographic region. It’s typically generated using random simulation techniques where the underlying parameter distributions are based on historical data and expert judgment.
For each event in the catalog, the models estimate the intensity at impacted locations using the event parameters in the catalog, site information and scientific formulas developed by the wider scientific community.
The model damage functions are used to estimate, for different intensity levels, the damages that will be experienced by different types of exposures.
The financial module applies policy and reinsurance terms to the “ground-up” losses to estimate gross and net losses to insurers.
Because the reference models in an open platform are the same as the traditional models, they do not require customization and can be used as they are. In this case, open models still offer the unique advantage of transparency on the assumptions driving your estimates. But insurers are finding there are assumptions that would benefit from customization—one example is the damage function component.
The traditional model vendors calibrate and “tune” the model damage functions utilizing the limited loss experience of a small number of insurers, and they don’t allow model users to access the damage functions in order to test this model component against their own claims experience. An open loss modeling platform gives insurers full access to the damage functions so that this important model component can be refined using the insurer’s detailed claims data. In this way, the model better reflects their actual loss experience.
Even insurers that do not have a lot of claims data will likely know the properties they underwrite better than a model vendor. For example, insurers that inspect properties or have written the same specialized books of business for decades can add that knowledge to the damage function component.
The other model component that should be directly under your control is the event catalog. The frequency and severity assumptions underlying the event catalogs are highly uncertain, yet they significantly impact your loss estimates, particularly your PMLs and TVaRs—probable maximum losses and tail values at risk. Much of the volatility in the loss estimates generated by the traditional models results from changes in the event catalogs.
Because they are generated by random simulation techniques in the traditional models, the event catalogs are subject to statistical variability. They are also subject to the differing opinions of scientists, so with a traditional model, your loss estimates can change significantly due to unwarranted volatility. Using a newer open platform you can lock down a consistent set of credible assumptions for your risk management decisions.
Building Models for New Peril Regions
It’s also straightforward to build new hurricane and earthquake models in an open loss modeling platform because two of the four model components—the intensity calculation and the financial module—may already be in place for all regions. Some open loss modeling platforms include the underlying data and scientific formulas to create high resolution wind and ground motion footprints based on detailed storm and earthquake parameters anywhere in the world. The built-in financial module will also likely have global application.
Using the most powerful open platforms, for a specific region, catastrophe modelers only need to construct:
- An event catalog.
- A set of damage functions.
Event catalogs begin with the historical event data, and the process starts with collecting the information from multiple data sources. For many peril regions, the historical data is readily available from government entities and scientific organizations.
Once the historical data is collected, cleaned and prepared for modeling, high resolution intensity footprints are automatically created for each event. A probabilistic catalog can be developed in multiple ways, such as perturbing historical events (changing the paths of past storms or the epicenters of past quakes, for example) or through simulation.
For damage function creation, the first step is to define the occupancy and construction types as well as any other building characteristics that will be used for the damage functions in that region. The U.S. damage functions can provide a “first pass” set of functions for the selected construction and occupancies. These functions can be modified based on actual claims data, engineering judgment and knowledge of local construction practices.
With the most advanced open loss modeling platforms the model building process essentially involves three steps: creating event catalogs, creating damage functions, and validating and calibrating the model with historical loss data adjusted to today’s values.
Taking Control
Significant advances in technology are enabling insurers to take greater control over the assumptions driving their catastrophe loss estimates. Insurers are using advanced open loss modeling platforms to build and customize their own catastrophe models that better reflect their own views of risk and actual loss experience.
The structure of an open model is the same as a traditional vendor model; the advancement is model assumptions are visible and accessible to the model users. This means you can:
- See the model assumptions.
- Understand the full range of valid assumptions for each model component.
- Analyze how different credible assumptions impact your loss estimates.
- Select the appropriate assumptions for your risk management decisions.
The benefits of an open platform include clarity on model assumptions, control over assumptions and significant cost savings. Open models provide the most efficient platforms for catastrophe risk management in light of the growing importance of the models and the increasing demands on insurers to take ownership of the risk.
 Hacked Hospitals, Hidden Spyware: Iran Conflict Shows Digital Fight in Warfare
Hacked Hospitals, Hidden Spyware: Iran Conflict Shows Digital Fight in Warfare  How Insurance Can Turn Maintenance Into Measurable Competitive Advantage
How Insurance Can Turn Maintenance Into Measurable Competitive Advantage  From Volatility to Value: How Carriers Can Build Durable Growth
From Volatility to Value: How Carriers Can Build Durable Growth  Hedge Fund Money Is Reshaping a 180-Year-Old Insurance Model
Hedge Fund Money Is Reshaping a 180-Year-Old Insurance Model 







