

















Hurricane Katrina was a deadly storm that caused a large loss to the insurance industry—but not so large that it shouldn’t have been anticipated by the catastrophe models.
Executive Summary
Model misses weren’t all caused by the failure to enter “floating casinos” and other specific exposures into catastrophe models, according to Karen Clark, who reports that advances in the art and science of modeling attack issues such as large loss potential outside of Florida with event estimates by location. Fine-tuned damage functions and transparent storm surge models also have developed in the wake of the storm.In the months after this historic hurricane, there was a lot of “model-bashing” because insurers felt the models had underestimated the risk and hadn’t prepared them for this event. Detailed investigations after Hurricane Katrina revealed three significant issues with the models and model usage:
1) Overreliance on the probable maximum losses (PMLs) from the models gave a false sense of security and led insurers to miss exposure concentrations in geographical areas not driving their PMLs.
2) The storm surge models were inadequate and did not address factors such as the breaching of the levees around New Orleans.
3) The catastrophe model damage functions were not suitable for all companies because they are calibrated to the historical claims data from a limited number of insurers. The model damage functions are necessarily biased to factors specific to individual companies, such as insurance-to-value assumptions, which vary widely from insurer to insurer, particularly for commercial properties.
In the aftermath of Katrina, insurers started applying factors to the catastrophe model loss estimates to “adjust” them for “model miss”—a relatively crude approach. Over the past 10 years, newer approaches and tools have entered the market to address these issues and advance the art and science of catastrophe modeling. This article reviews the lessons of Hurricane Katrina and how this storm drove innovation that is now significantly impacting how insurers assess and manage catastrophe risk.
Additional Risk Metrics for Monitoring and Managing Large Loss Potential
Since the first catastrophe models were developed, the primary model output has been the Exceedance Probability (EP) curve, which is generated by simulating many random events and estimating the losses from those events. The events are simulated in accordance with their relative probabilities of occurrence so the EP curves show the chances of exceeding losses of different magnitudes.
While EP curves give a lot of valuable information, the insurance industry, including rating agencies and regulators, have focused on a few point estimates from those curves—namely the 1.0 percent and 0.4 percent probabilities of exceedance. These so-called “1-in-100-year” and “1-in-250-year” PMLs drive many important risk management decisions, including reinsurance purchasing and capital allocation.
While the PMLs may be well suited to these decisions, these numbers do not give insurers a complete picture of large loss potential, as Katrina illustrated very clearly. For example, insurers writing along the Gulf and Florida coastlines will likely have PMLs driven by Florida events because that’s where severe hurricanes and losses are most frequent. While managing the PML driven by these events, an insurer could be building up dangerous exposure concentrations in other areas along the coast. The traditional catastrophe models are not the right tools for monitoring exposure accumulations.
Exposure concentrations can be more effectively identified and managed using a scientific approach that’s the flip side of the EP curve approach. In the Characteristic Event (CE) methodology—developed in the wake of Katrina—the probabilities are defined by the hazard and the losses estimated for selected return period events.
The chart below shows the losses for the 100-year hurricanes for a hypothetical insurer. The landfall points, spaced at 10-mile intervals along the coast, are shown on the x-axis; the estimated losses, in millions of dollars, are shown on the y-axis. The dotted line shows the 100-year PML—also corresponding to the top of this company’s reinsurance program.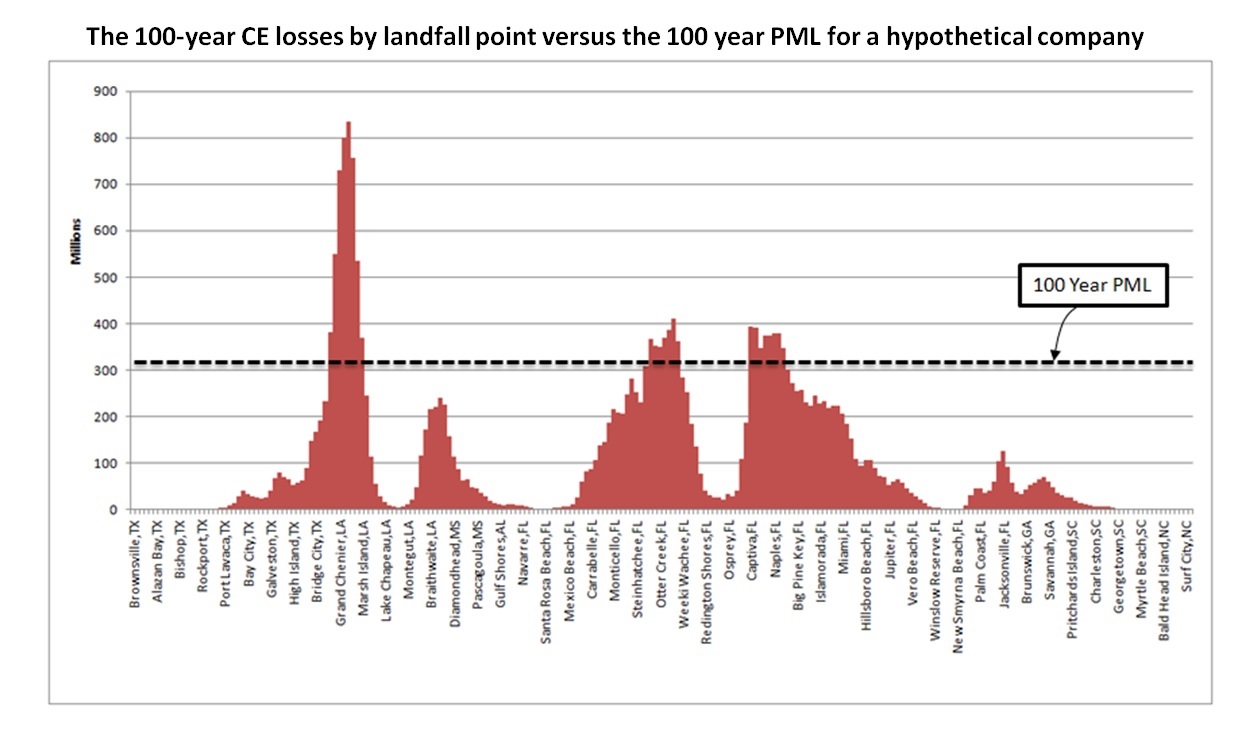
The CE chart clearly shows that although the insurer has managed its Florida loss potential quite well, the company has built up an exposure concentration in the Gulf, and should the 100-year hurricane happen to make landfall in certain locations in Texas or Louisiana, this insurer will have a solvency-impairing loss well in excess of its PML and reinsurance protection.
Armed with this additional scientific information, insurers can enhance underwriting guidelines to reduce peak exposure concentrations. Because they represent specific events, the CEs provide operational risk metrics that are consistent over time. The CEs also clearly identify growth opportunities—areas where insurers have relatively low loss potential and market penetrations.
One important lesson of Katrina is that insurers require multiple lines of sight on their catastrophe loss potential and cannot rely on the traditional catastrophe models alone. CEOs and boards in particular want to know where they can have surprise and outsized losses relative to peer companies. Given the uncertainty surrounding catastrophe loss estimation, the more credible information, the better.
Estimating Storm Surge Losses
Hurricane Katrina caused tens of billions of dollars in flood damage. Even though only a fraction of this damage was insured, insurers that didn’t cover flood and storm surge losses still were impacted indirectly through infrastructure damage, supply disruptions, etc.
Estimating storm surge losses requires models that have higher resolution and are more detailed than those estimating the wind impacts of hurricanes. In particular, knowledge of defenses such as sea walls and levees along with high-resolution elevation data is required to credibly calculate the inland water depths and losses. This information is now much more readily available than it was before Katrina.
Because of the sensitivities of high-resolution models, even if two models rely on the same scientific data, slight variations in model assumptions can lead to vastly different loss estimates, particularly for an individual insurer. This means that fully transparent storm surge models are a necessity for insurers to truly understand and control flood risk.
Traditional catastrophe models are “black boxes” to users because the modeling companies consider their models to be proprietary. This may have been an appropriate paradigm in the earlier days of modeling, when model vendors had to expend a lot of effort and resources to collect and prepare the data required for a model. For example, before Katrina, high-resolution elevation data cost tens of thousands of dollars and was difficult to obtain and piece together for modeling purposes. But today, 10 years after Katrina, most of the scientific data is in the public domain and readily accessible, in many cases already in the format required for modeling.
Most of the data underlying catastrophe models is not proprietary to the model vendors, and full transparency means being able to see every important model assumption and verify the model calculations. Transparency no longer means reading hundreds of pages of documentation that may or may not accurately reflect how the model behaves under different scenarios.
The Importance of Insurer Exposure Data to the Model Loss Estimates
After Katrina, the issue of exposure data quality also became a hot topic. The theory was that insurers didn’t get good modeled estimates of their Katrina losses because they weren’t entering high-quality exposure information into the catastrophe models.
To some extent this was the case, and there were examples of the “floating casinos” that weren’t coded properly. Certainly, exposure data quality has improved since Hurricane Katrina.
But the more pervasive problem is that model vendors calibrate and “tune” the model damage functions—a primary component of the model and key driver of loss estimates—utilizing the loss experience of a limited number of insurers. This subset of insurers may not be representative of the entire market or the spectrum of property business, and even within this small subset, each insurer has different insurance-to-value assumptions, policy conditions and claims handling practices. This means that the wind damage to a specific property will result in a different claim and loss amount depending on which insurer underwrites the property, and the model damage functions will be biased to the data available to the model vendors.
Even if a modeler could “correct” for these inconsistencies, it’s not clear what ultimate function should be used for the model. Whatever decisions a model vendor makes, the damage functions in a traditional vendor model will be averaged over a small subset of companies and will not apply to specific companies.
The best way to resolve this issue is to enable insurers to see and access the damage functions and test this model component against their own claims experience. Then insurers can do their own damage function calibration so the model loss estimates better reflect their actual loss experience.
The traditional model vendors don’t allow this, but newer models do. Today, advanced open platforms empower model users to refine the model assumptions directly and scientifically—not through rough factors applied to the model output.
Conclusion
Hurricane Katrina didn’t cause an extreme insured loss, but the impact on the industry has been great. Katrina brought to the surface many of the challenges in building and using catastrophe models and ignited the fuel for game-changing innovation in the catastrophe modeling industry. The introduction of new risk metrics, new models and tools has created a paradigm shift that is significantly advancing the art and science of modeling.
 U.S. E&S Growth Slows Again; Declining Berkshire Volume Tops Leaders
U.S. E&S Growth Slows Again; Declining Berkshire Volume Tops Leaders  Reinsurers Least Successful Acquirers in Industry M&A: Analysis
Reinsurers Least Successful Acquirers in Industry M&A: Analysis  How Insurance Can Turn Maintenance Into Measurable Competitive Advantage
How Insurance Can Turn Maintenance Into Measurable Competitive Advantage  Is Commercial Auto Having Its ‘Sprinkler Moment’?
Is Commercial Auto Having Its ‘Sprinkler Moment’? 










