


















In the United States, severe convective storms (SCS)—also known as severe thunderstorms, which can include tornadoes, hail and strong localized wind gusts—cause average annual insured losses of more than $12 billion. Actual annual losses fluctuate from year to year, and in 2011, severe thunderstorm losses in aggregate exceeded $27 billion with two major events costing more than $7 billion each. (Source: 2016 Munich Re, NatCatSERVICE; Property Claim Services; Insurance Information Institute)
Executive Summary
Catastrophe models for severe convective storms have existed for decades, but the model loss estimates lack credibility for most insurers. Here, Karen Clark explains why and suggests a new modeling approach.Wind losses are now responsible for well over a third of all losses for U.S. property insurers, and individual severe thunderstorm events routinely cause more than $1 billion in damages. While this is not a big number for the industry as a whole, severe thunderstorms are typically localized events, which means individual insurers can be impacted disproportionately. Even though these events occur every year and insurers have a wealth of claims data, there’s still a lot of uncertainty surrounding the “tail” of the distribution and the potential for and probability of large losses.
Catastrophe models for severe thunderstorms have existed for more than 20 years, but the SCS models still do not produce reliable numbers for most insurance companies. There are a number of reasons why this peril is particularly difficult to model. Most notably, severe thunderstorms are high-frequency but relatively low-severity events. There are thousands of tornado touchdowns, hailstorms and localized pockets of high winds every year. But the catastrophe models were designed to estimate losses from low-frequency, high-severity events.
The traditional catastrophe models also work better for events that are geographically large relative to the resolution of the exposures. For example, hurricanes and earthquakes cover wide areas in generally predictable patterns. The intensities at particular locations can be estimated using standard scientific formulas. In contrast, even though a severe thunderstorm occurrence can impact a very wide area, the damage producing phenomena—e.g., an individual tornado or hailstorm—may cover only a few square blocks or less, and there can be gradations of damage within that small area.
Catastrophe modelers rely on historical meteorological data, and there are several problems with the scientific data for severe thunderstorms. For one, there is no meteorological definition of an “event” or “occurrence.” The National Weather Service tabulates the numbers and locations of individual tornadoes, hailstorms and severe wind reports by day without any regard to grouping these into meteorological events useful for insurance purposes.
Another issue is that because individual tornadoes and hailstorms are typically very small, most of the reporting has been in and around populated areas. Even with modern weather-detection equipment, tornadoes and hailstorms can go unreported in sparsely populated areas, and this means the historical data gives an incomplete and biased picture of the true frequency by location.
As a result of these shortcomings, traditional models have tended to produce numbers that are too low relative to actual loss experience, and insurers have little confidence in them. While the models work reasonably well for the industry as a whole, individual insurers can experience actual losses every few years that are as high as the model-generated losses in the extreme tail of the loss distributions. For example, an insurer may have experienced two model-generated “1,000-year losses” over the past 10 years.
This is because the random simulation techniques employed by the traditional catastrophe models do not treat individual locations consistently. Areas of exposure concentration can be missed entirely, significantly underestimating the loss potential. Given all of these challenges, a new approach is warranted for modeling SCS.
Estimating Small Losses, Super Tornados and Super Outbreaks
Relative to most types of catastrophes, insurers have an abundance of actual loss data for severe thunderstorms. There are many small losses every year and typically enough data for actuaries to estimate expected annual losses by state, for example. Actuaries may have less confidence in the loss data at higher geographical resolution, such as rating territories, and for informing the tail of the distribution. This is where a new modeling approach can add significant value.
Instead of generating thousands of random events, the Characteristic Event (CE) approach can be used to define return-period scenarios and intensity footprints for severe thunderstorms. These footprints can then be superimposed on property exposures to estimate the resulting losses.
With respect to large losses, insurers need to be concerned about two types of extreme events: an event dominated by a very large and strong tornado, or a Super Tornado, and a Super Outbreak of hundreds of localized tornadoes, hailstorms and high winds.
Recent examples of Super Tornado events include the 2011 Joplin, Mo., and 2013 Moore, Okla., tornadoes. But the most extreme historical event of this type was the Tri-State Tornado of 1925 that cut a path of destruction through parts of Missouri, Illinois and Indiana with a path length over 200 miles. It’s not known for certain, but it’s believed this tornado maintained the maximum F5 intensity along most of its track. Evidence of this is that most towns along the track were completely destroyed.
The graphic below shows the Tri-State Tornado track, which given the historical record, can be considered a 100-year Super Tornado event. Karen Clark & Co. estimates this tornado would cause about $6 billion in insured losses if it occurred today. This is useful information, but could the losses be higher if this Super Tornado occurred somewhere else?
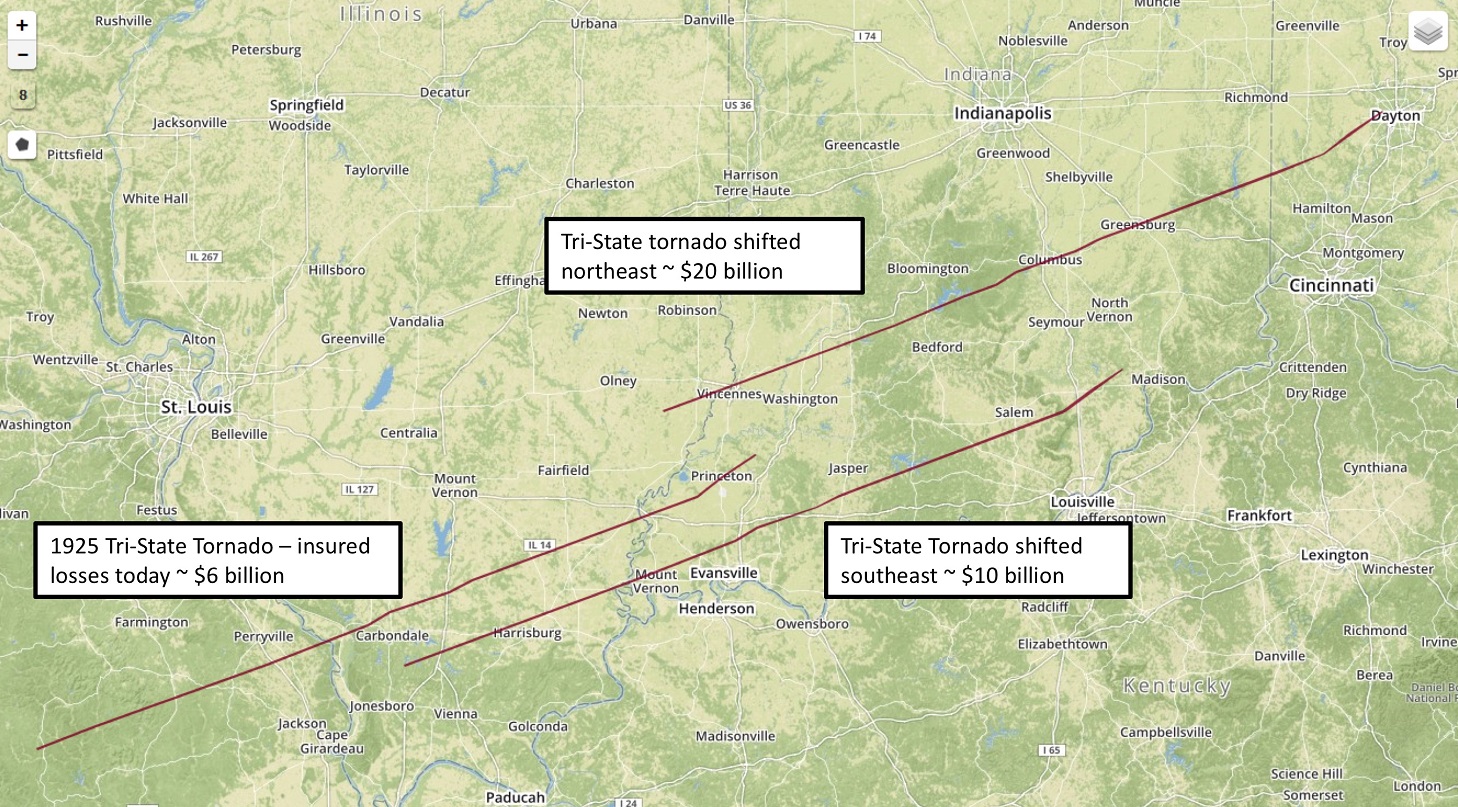
In the CE approach, the 100-year footprints are floated uniformly across a geographical area of interest to ensure complete and consistent spatial coverage. In this way, insurers get a robust distribution of their potential losses from the 100-year CEs rather than one deterministic number. Individual locations are not under- or overpenalized due to random sampling techniques and exposure concentrations that can result in solvency-impairing losses are revealed.
The graphic also shows the Tri-State Tornado in two other locations. This Super Tornado with a track shifted to the southeast toward Evansville, Ind., could cause losses of $10 billion. A northeast shift putting the track through several towns in Indiana, including Vincennes, Columbus and Greensburg, could cause over $20 billion in insured losses. As with all types of catastrophes, the key driver of losses is location, which is why the CE approach is more robust than random simulation.
What about a Super Outbreak? Until a few years ago, the benchmark Super Outbreak was the April 3-4, 1974 event. This event still holds the record for the most violent outbreak ever recorded with 30 confirmed F4/F5 tornadoes over a two-day period. In all, there were 148 tornadoes across 13 states and dozens of hail and severe wind reports.
The April 25-28, 2011 Super Outbreak now holds the record for the highest number of tornadoes spawned by one meteorological event with 363 confirmed tornadoes. Fifteen of these tornadoes were classified as F4 or F5. KCC estimates this event would cause nearly $8 billion in losses today, and by dynamically modeling this event, we can determine it could cause as much as $20 billion or as little as $3 billion, depending on the location and impacted area.
In the CE approach, many different intensity footprints are created to represent different return period events. Through this process of dynamic event modeling, a reliable sample of simulated events is created, including Super Tornadoes and Super Outbreaks. Insurer claims data can then be used to fine-tune the damageability component of the model.
Actuaries can use actual loss experience to make sure the model produces reliable loss estimates for recent events. Instead of being separate from the modeling process, the loss data can be incorporated into model development. The severe thunderstorm loss data has as much or higher credibility relative to the other model assumptions. Once the model has been tuned using small events, insurers can have more confidence in the tails of the model-generated loss distributions.
Actuaries have generally left the development of catastrophe models to the external model vendors. But this has not led to credible models for SCS, and actuaries have larger roles to play in ensuring their companies have robust models and loss estimates for severe thunderstorms.
As catastrophe losses become an increasing proportion of property losses, new modeling technology is warranted to help insurers better understand and manage large-loss potential—particularly for difficult-to-model perils, such as SCS. Models are not reality; they are tools based on many assumptions. By being more engaged in the model development process, company actuaries and other experts will be more knowledgeable about those assumptions and how they impact the loss estimates. Being more informed on and in control of model assumptions will lead to higher confidence in pricing, underwriting and risk management decisions.
More articles by Karen Clark
- Earthquakes for CEOs: Understanding the Most Recent USGS Report
- How to Build Your Own Catastrophe Model
- What Boards Would Like to Know About Catastrophe Losses
- What Rating Agencies Really Want to Know About Your Catastrophe Risk
- The Current Scientific Consensus on Climate Change and Hurricanes—It May Surprise You
 From Volatility to Value: How Carriers Can Build Durable Growth
From Volatility to Value: How Carriers Can Build Durable Growth  Hedge Fund Money Is Reshaping a 180-Year-Old Insurance Model
Hedge Fund Money Is Reshaping a 180-Year-Old Insurance Model  How Insurance Leaders Can Leverage AI Without Sacrificing Trust
How Insurance Leaders Can Leverage AI Without Sacrificing Trust  Strong El Nino, Warmer Sea Impacts Atlantic Hurricane Season Forecasts
Strong El Nino, Warmer Sea Impacts Atlantic Hurricane Season Forecasts 



